Avant-propos
Pour plus d’information et un code source, vous pouvez aller sur mon dépôt git:
Sommaire
- Définition
- Fonctionnalités
- Fonctionnement
- Représentation binaire
- Utilisation
- Pseudo-Code
- Bonus – Comptage de la position
Définition
L’algorithme LZ77 est un algorithme de compression sans perte utilisant une fenêtre glissante.
On peut le retrouver sous différent nom comme Lempel Ziv 77 ou LZ1.
- Une compression sans perte est une méthode de compression qui restitue après la décompression la même donnée que l’original.
- Une compression par fenêtre glissante utilise une zone mémoire de recherche qui peut se mouvoir, cela évite à l’algorithme d’être trop gourmand en ressources.

Fonctionnalités
Comme on l’a vue précédemment, l’algorithme LZ77 utilise une fenêtre glissante comme l’a majorité des algorithmes de la famille LZ.
Cette fenêtre glissante est coupée en deux parties, une partie qui est le tampon et une autre qui le dictionnaire.
Le tampon est la partie lecture et le dictionnaire est la partie recherche.

Le but de cet algorithme est d’encoder une récurrence qui se trouve dans le tampon et le dictionnaire par la combinaison position/taille.

Fonctionnement
Le fonctionnement est simple, trouver le plus grand motif du tampon dans le dictionnaire.
Pour illustrer ça, on va prendre un exemple:
Dans le tampon = “AABBCC”
Dans le dictionnaire = “RRYYIIAANNMMXX”
On commence à chercher:
- AABBCC
NOT FOUND - AABBC
NOT FOUND - AABB
NOT FOUND - AAB
NOT FOUNDAA
FOUND RRYYIIAANNMMXX
On calcule la distance du motif trouvé jusqu’au tampon de lecture.
“RRYYIIAANNMMXX” = 8
La longueur du motif trouvé est 2 (AA) et le prochain caractère du motif dans le tampon est B alors pour l’encodage on obtient (8, 2, B).
Si aucun motif est trouvé, l’encodage sera comme ça (0, 0, [premier caractère du tampon]), alors si aucun motif est trouvé dans l’exemple précédent, l’encodage sera (0, 0, A).
Pour résumer, si on trouve un motif ([distance], [taille], [prochain caractère]) et si aucun motif est trouvé (0, 0, [premier caractère du tampon]).

Sur de la petite donnée, la partie encodée peut être plus grande que la donnée originale.
Mais sur de la grande donnée comme les misérables de Victor Hugo (tome 1):
- Fichier original: 710 kilobytes
- Fichier compressé: 420 kilobytes
Soit 40% de compression.

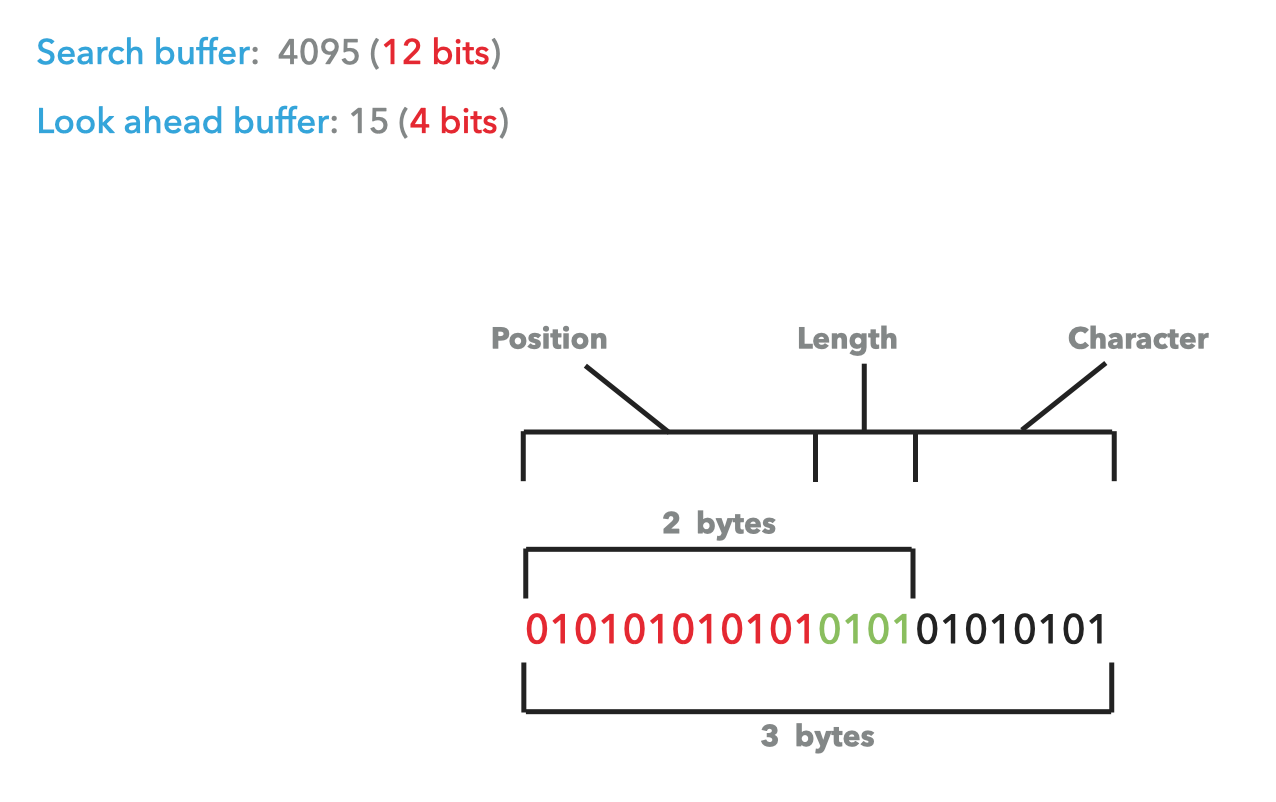
Représentation binaire
Pour la représentation binaire, les valeurs communément utilisées sont:
- Dictionnaire: 12 bits soit 4095.
- Tampon: 4 bits soit 15.
Soit encodé sur 2 octets.
Utilisation
Le LZ77 n’est plus utilisé, la forme LZSS sera privilégiée qui est une grande amélioration au niveau du taux de compression mais aussi au niveau rapidité compression/décompression.
Pseudo-Code
Voici un pseudo pour la partie compression:

Et la partie décompression:

Merci d’avoir lu cet article sur l’algorithme LZ77 qui est la première pierre à la construction d’une série d’algorithmes qui ne cessera d’optimiser la compression par dictionnaire.
Bonus – Comptage de la position
Il y a principalement 2 formes de comptage de la position.
Ce que j’appelle absolute qu’on compte à partir du début du dictionnaireExemple avec la phrase : “je suis ici et je suis là-bas” de 29.
| — 8 — |
La phrase encodée : `je suis ici et (0,8)là-bas`.
| — 0
Et le format relative compte à partir de l’index courant.Exemple avec la phrase : “je suis ici et je suis là-bas” de 29.
| — 8 — |
La phrase encodée : `je suis ici et (0,8)là-bas`.
| —– 15 —– |
Dans la plupart des utilisations, le mode relative est utilisé.
